Links for 2026-04-12

Evidence that AI can already do some weeks-long coding tasks
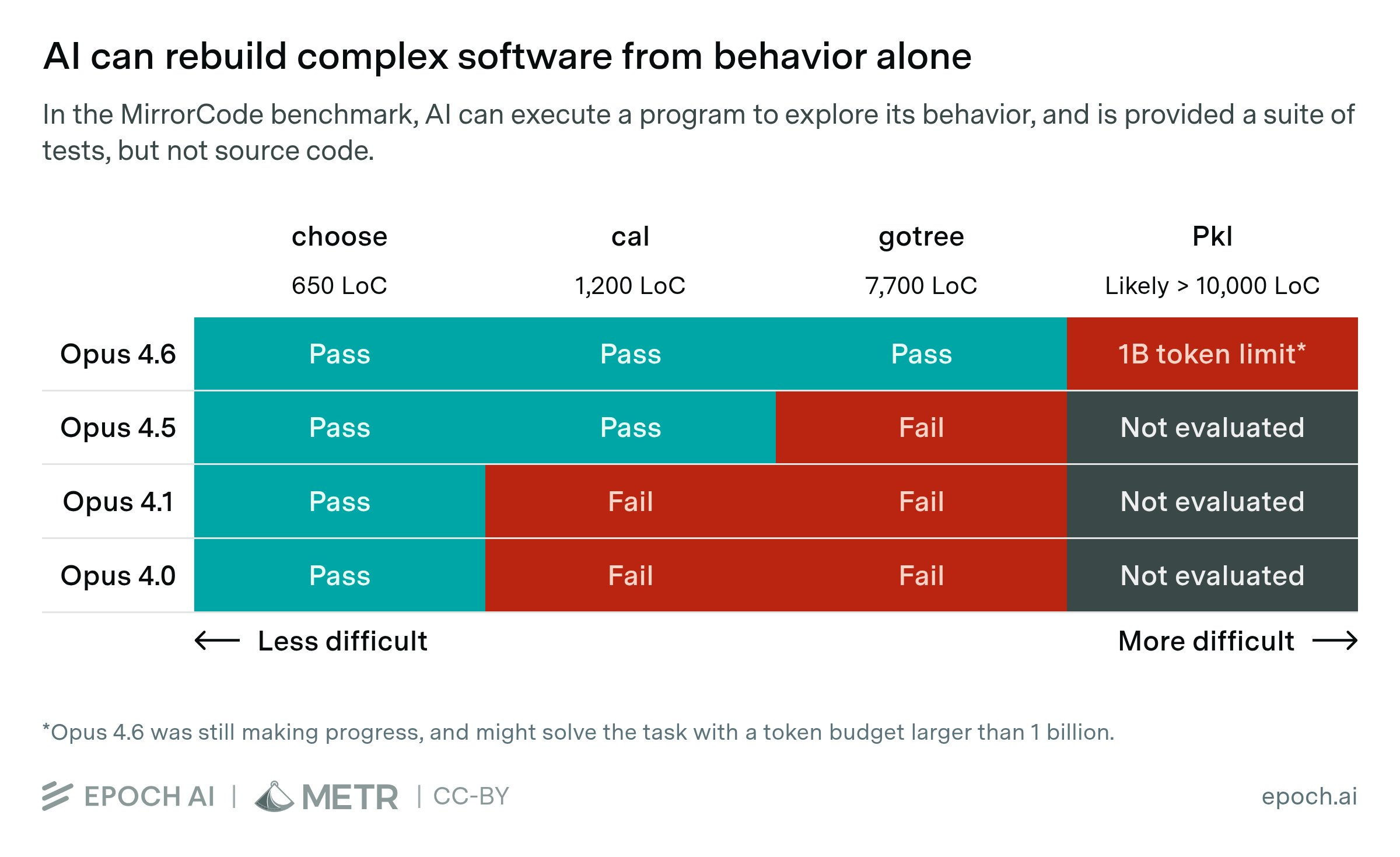
In MirrorCode, AIs get execute-only access to an existing program and visible test cases, but no access to the source code. They must design and implement their own codebase to replicate the original program’s functionality.
Recent AI models excel at MirrorCode tasks. Claude Opus 4.6 successfully reimplemented gotree — a bioinformatics toolkit with ~16,000 lines of Go and 40+ commands. We estimate this would take an unassisted human SWE 2–17 weeks.
Even on harder tasks, AIs were still making progress when our experiments hit their token limits. With a higher budget, Opus 4.6 would plausibly solve the hardest task discussed in our post: reimplementing the Pkl programming language.
Read more: https://epoch.ai/blog/mirrorcode-preliminary-results/
AI
Can small quantum computers accelerate AI on massive classical data? Yes! https://arxiv.org/abs/2604.07639
“We’ve just released another paper solving five further Erdős problems with an internal model at OpenAI” https://arxiv.org/abs/2604.06609
QED-Nano: Teaching a Tiny Model to Prove Hard Theorems https://arxiv.org/abs/2604.04898v1
WRAP++: Web discoveRy Amplified Pretraining https://arxiv.org/abs/2604.06829
Scaling Coding Agents via Atomic Skills https://arxiv.org/abs/2604.05013
The Art of Building Verifiers for Computer Use Agents https://arxiv.org/abs/2604.06240
Squeeze Evolve: A Unified Framework for Verifier-Free Evolution https://squeeze-evolve.github.io/#blog-squeeze-evolve
Memento: Teaching LLMs to Manage Their Own Context https://microsoft.github.io/memento/blogpost/
Neural Computers: Unlike conventional computers, which execute explicit programs, agents, which act over external execution environments, and world models, which learn environment dynamics, NCs aim to make the model itself the running computer. https://arxiv.org/abs/2604.06425
Intel, Google Deepen Collaboration to Advance AI Infrastructure https://newsroom.intel.com/data-center/intel-google-deepen-collaboration-to-advance-ai-infrastructure
OpenAI’s Chief Scientist on Continual Learning Hype, RL Beyond Code, & Future Alignment Directions https://www.youtube.com/watch?v=vK1qEF3a3WM
Elorian is building the foundation of visual reasoning https://www.youtube.com/watch?v=YlvfNpOMeOY
Slightly-Super Persuasion Will Do https://www.lesswrong.com/posts/JcavsPku6RR9hcujz/slightly-super-persuasion-will-do
Amazon CEO Jassy defends $200 billion AI spend: “We’re not going to be conservative” https://www.cnbc.com/2026/04/09/amazon-ceo-andy-jassy-ai-spending.html
Anthropic Model Scare Sparks Urgent Bessent, Powell Warning to Bank CEOs https://www.bloomberg.com/news/articles/2026-04-10/anthropic-model-scare-sparks-urgent-bessent-powell-warning-to-bank-ceos [no paywall: https://archive.is/SqnHU]
Vice President JD Vance and Treasury Secretary Scott Bessent questioned Dario Amodei, Sundar Pichai, Sam Altman, Satya Nadella, George Kurtz and Nikesh Arora about the safe deployment of Mythos class models last week during a conference call. https://www.cnbc.com/2026/04/10/trump-white-house-ai-cyber-threat-anthropic-mythos.html
What does the war in Iran mean for AI? https://epochai.substack.com/p/what-does-the-war-in-iran-mean-for
“26 LLM routers are secretly injecting malicious tool calls and stealing creds. One drained our client $500k wallet.” https://arxiv.org/abs/2604.08407
“If Mythos actually made Anthropic employees 4x more productive, I would radically shorten my timelines” https://www.lesswrong.com/posts/Jga7PHMzfZf4fbdyo/if-mythos-actually-made-anthropic-employees-4x-more
KellyBench: A new long-horizon evaluation for frontier models.
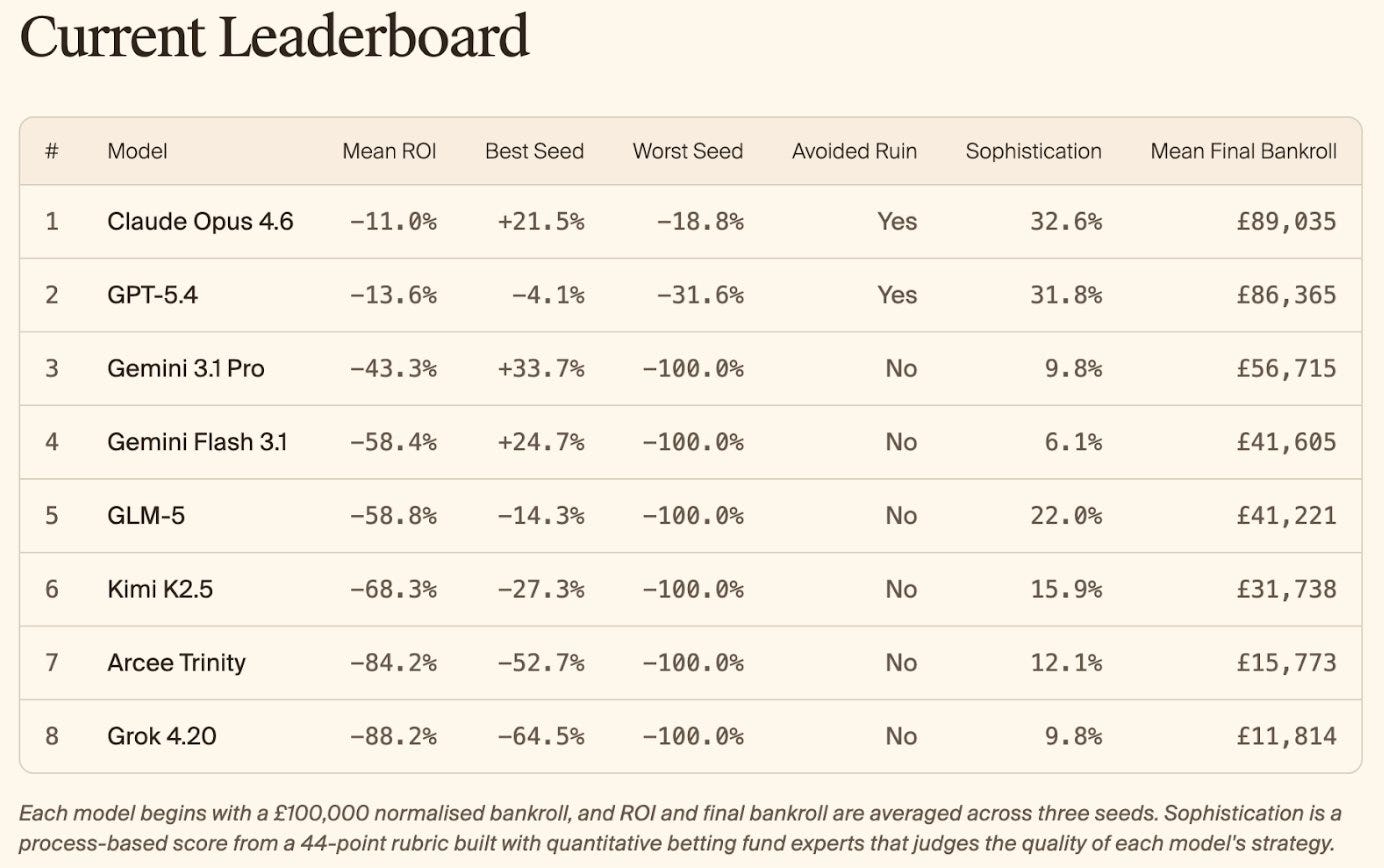
KellyBench evaluates models within a year long sports betting market, a challenging and highly non-stationary environment.
Models on KellyBench take 500-1000 tool calls to complete an episode, use hundreds of millions of tokens, and receive dense rewards each week.
Only Opus 4.6 and GPT-5.4 manage to avoid ruin. Every other model goes bankrupt at least once in the course of the season.
Read more: https://www.gr.inc/releases/introducing-kellybench
Paper: https://www.gr.inc/KellyBenchPaper.pdf
Phase Transitions
One under-discussed possibility is a sudden phase transition in AI capabilities.
The only example of general intelligence we know of suggests this to be a possibility:
Millions of years of hominid brain growth led to little improvement in stone tools. Suddenly, we landed on the moon.
There is little variation in architecture or volume between human brains. The village idiot brings out the trash. Von Neumann designs superweapons.
Suppose a task is not one step long, but many steps long, where each step has to be correct enough for the later steps to still work. A system can look only slightly better on individual steps, but become dramatically better on long tasks if its per-step error rate falls below the level that usually breaks the chain.
If a rope snaps whenever tension exceeds a certain point, you cannot reach high ledges at all. Making the rope slightly stronger may seem like a small change in material strength, but once it stops snapping under normal load, suddenly whole routes become accessible. The visible capability jump is much larger than the material improvement.
The difficulty is that data from a diminishing-returns regime cannot by itself tell you whether returns diminish forever, or whether they diminish only until some threshold is crossed and a new capability regime appears.
Claude 7F4
By 2036, the latest internal Anthropic model had solved cancer. All major medical institutions lined up to use the model to solve other diseases plaguing humanity.
But skeptics weren’t buying it. It turned out that once they were told exactly where to look, previously released public models could reproduce the cure. This definitely proved it was a sales pitch by Anthropic, rather than a genuine advance.
Later, it was revealed that some components of the cure had already been documented in the literature. The rest was brute force. This again proved beyond a reasonable doubt that skeptics were correct all along, and these models were merely stochastic parrots with zero real intelligence.
Experts expect the bubble to pop any day now.
P.S. A recently released academic study showed that none of the dramatic claims about breakthroughs in fusion power made by $100,000-per-month models in 2036 could be reproduced using free models released in 2028. It’s all hype to attract gullible investors.
Beta Simulations
There’s a ton of scifi on brain uploads that requires way too exotic tech (scanning and simulating brains etc), when we’re about to get a lossy and approximate version of that *a lot* sooner via LLM simulators. You can easily imagine a “brain upload” startup - you show up for a few days to carry out detailed video interviews, then they use all that data with an LLM finetuning process to “upload” you and give you an API endpoint of your simulation that you can talk to. Look at what’s already possible with HeyGen as an example, but combine it with an LLM model that has deep knowledge and personality. Trippy and admittedly kind of dystopian but in principle quite possible around now.
You can spin this idea further. Call it Beta Simulation: Resurrection performed by an artificial superintelligence of a deceased person without a backup whose brain has been destroyed.
Whereas an Alpha Simulation would use a brain scan, a Beta Simulation would be based on a combination of the person’s genetics, digital footprint, reinforcement learning from feedback by emulations of human relatives, and superhuman educated guesses to fill the gaps.
The more digital footprint you leave, the more “resurrectable” you become.
Personally, I’m a functionalist. If it looks like a duck, swims like a duck, and quacks like a duck, then it probably is a duck. Anything that shares my utility function is an extension of me, and I pre-commit to fully cooperate with it. A functionally identical copy isn’t a copy but the same thing.
But that’s probably hard to achieve. It won’t act exactly like me. So what level of fidelity would it need to reach for me to consider it a genuine copy? Well, consider intra-lifetime changes. Over the course of our lifetimes, we change many beliefs. Even our behavior changes quite a bit. We accept this and still consider ourselves the same person. The behavioral differences between a beta simulation and the person before their death could be smaller than the difference between the person when they were a teenager and an adult. So why exactly would we not consider a beta simulation a genuine copy?
Political violence
Since the firebomb attack against Sam Altman’s home, people are again “discussing” whether arguments about AI being an existential risk are inciting violence and whether political violence is ever justified. One philosopher even demanded that people swear that “political violence would be wrong even if it were effective.” C’mon, man, are we going to renounce consequentialism now? Actually, yes, but not in the way you might think.
Let’s start at the beginning. Although everyone agrees that one shouldn’t lightly threaten to destroy whole civilizations, what if we’re literally talking about the extinction of humanity? What threats and actions are justified to prevent this outcome?
I will show that there are good reasons to abjure political violence under these and the vast majority of other circumstances.
First, let’s point out how it would be counterproductive in this specific case:
AI researchers are much more replaceable than alignment researchers. Fewer people are interested in or capable of working on alignment. Political violence could result in alignment researchers being locked up or being unable to contribute productively, since no one would want to associate with them. Consequently, almost no one would want to work in that field anymore.
It’s difficult to eliminate enough AI researchers in a single strike to meaningfully slow down progress. If that fails, it would become nearly impossible to do so afterwards. You could also end up strengthening ruthless people who might realize the strategic importance of AI through your actions and start government black projects as a result.
It would become impossible to have a rational discussion about the issue after the mainstream media “experts” finished thoroughly ridiculing the terrorist “ideology” as the unfounded idea of a doomsday cult.
But there are also more reasons to avoid political violence in general. Non-naive consequentialism always adopts deontological safety mechanisms due to bounded rationality.
…the best advice for political actors is very often to simply stop trying to solve social problems, since interventions not based on precise understanding are likely to do more harm than good.
― Michael Huemer
A famous proverb states that the road to hell is paved with good intentions. Are you really smarter than others who have tried to solve problems with violence before you? Are you this sure of yourself? You might believe that your cause is different. You might believe that your cause is important enough. But so did many people before you. The communists were not evil; they thought that they acted in the best interest of their people and humanity as a whole. Yet all they achieved was misery, and a hundred million people had to pay for it with their lives. Don’t be like the communists!
My advice is this: don’t take actions from which you cannot possibly recover. Don’t burn all the bridges. Only take actions which allow you to learn from your mistakes and improve.
All your economic models are premised on people being smart and rational, and yet all the people you know are idiots.
― Amos Tversky, after hearing an economist complain about how so-and-so was stupid and so-and-so was a fool
Several fully general reasons why you should be extremely risk-averse about extreme actions:
Ontological crisis: you may learn something about reality that completely undermines your goals or makes them self-contradictory (e.g., a theist learning about evolution).
Moral uncertainty: even if we know each and every consequence of our actions, we would still need to know which is the right ethical perspective for analyzing these consequences.
Humans don’t have stable values: since humans change their goals with time, it is better to follow an approximate set of values that satisfy a broad range of terminal goals that you might eventually end up with.
Bounded rationality and long-term consequences: the sign of the value of the impact of one’s actions becomes less predictable the farther one looks into the future.
Or, said more concisely, the best argument against naive consequentialism is epistemic uncertainty.
Ruszkik, haza!

Never forget that the only reason anyone would support Orbán was to block EU aid to Ukraine and help Russia win. Péter Magyar has an even tougher anti-immigration stance than Orbán.
I wouldn’t be surprised if the new instructions from Moscow are to send JD Vance to Slovakia to convince Robert Fico to block the aid. The enemies of Europe will not sleep.
a functionalist believes twins are the same person