Links for 2026-01-25

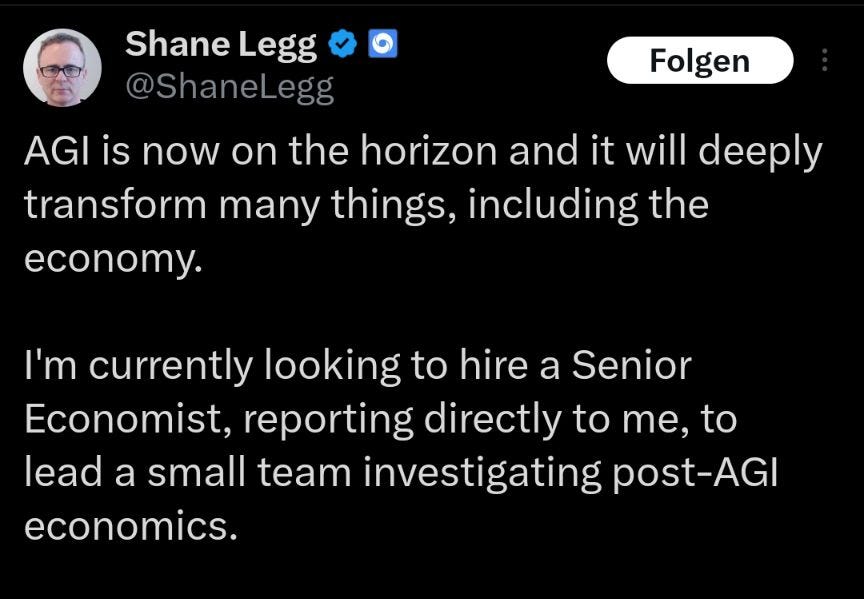
Learning to Discover at Test Time
To solve hard discovery problems, which require ideas beyond a model’s training data, an AI must learn from its experience during the attempt to solve the problem.
Unlike prior methods like AlphaEvolve, which search for solutions by prompting a frozen LLM, TTT-Discover performs Reinforcement Learning at test time on one target problem.
Across several domains, this produces solutions that match or exceed the best existing human baselines:
The method optimized GPU kernels for matrix operations, achieving runtimes significantly faster than human implementations.
The method was tested on AtCoder Heuristic Contests, where it achieved scores superior to the best human submissions in past contests.
Applied to single-cell RNA-sequencing data it surpassed the human expert benchmark.
It improved the best known bounds on Erdős’ minimum overlap problem and the first autocorrelation inequality.
Everything was achieved using an open-weights model and public code.
Project page: https://test-time-training.github.io/discover/
AI
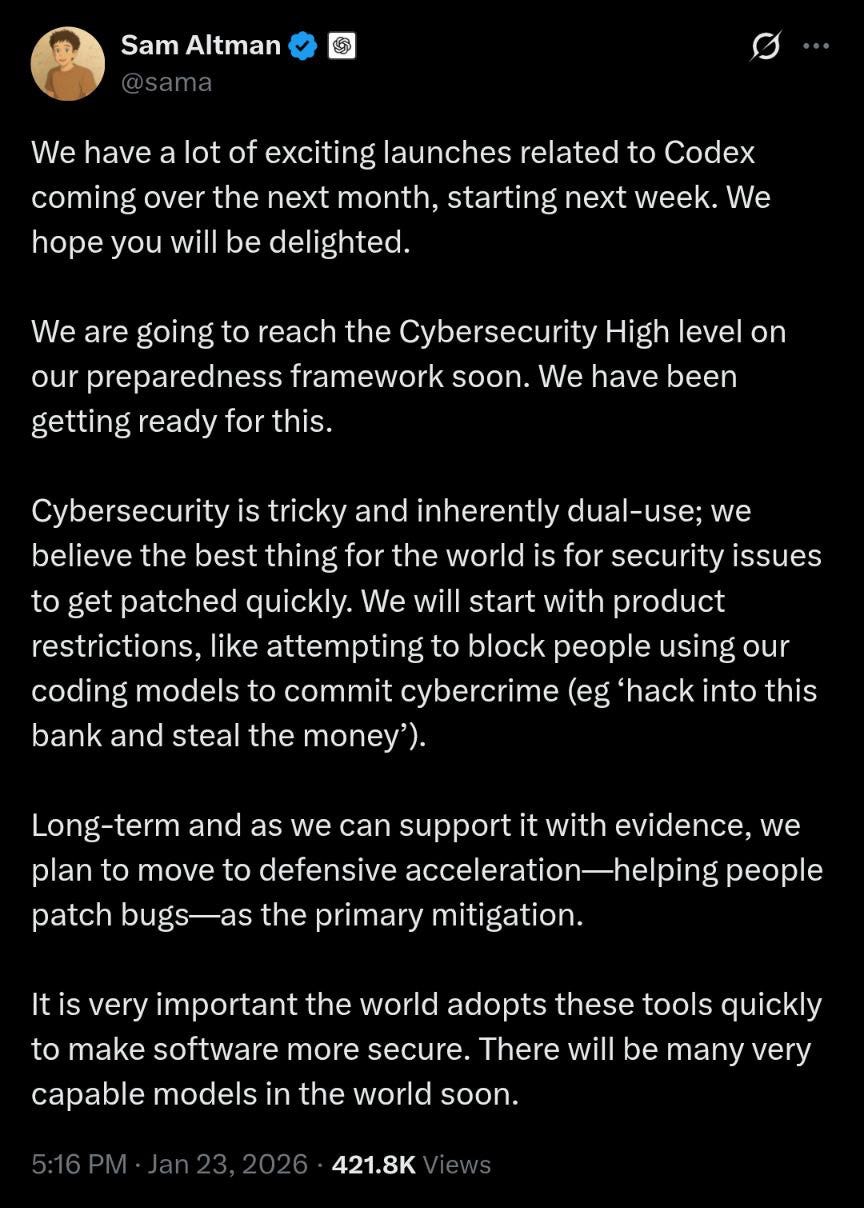
New record on FrontierMath Tier 4 https://epochai.substack.com/p/new-record-on-frontiermath-tier-4
In-the-Wild Compliant Manipulation with UMI-FT https://umi-ft.github.io/
CoinFT: A Coin-Sized, Capacitive 6-axis Force/Torque Sensor for Robotic Applications https://coin-ft.github.io/
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning https://research.nvidia.com/labs/dir/cosmos-policy/
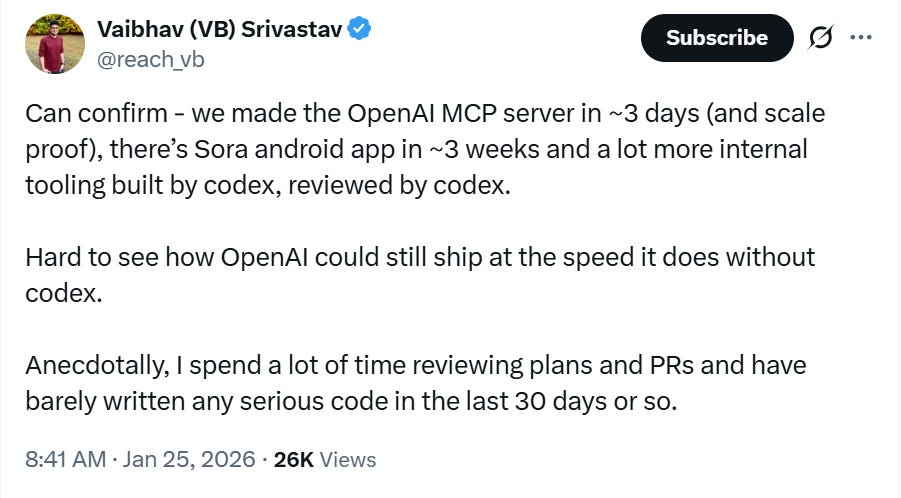
VibeTensor: System Software for Deep Learning, Fully Generated by AI Agents https://github.com/NVlabs/vibetensor
Confucius Code Agent: Scalable Agent Scaffolding for Real-World Codebases https://arxiv.org/abs/2512.10398
Anthropic reveals the “Constitution” that governs Claude’s behavior https://www.lesswrong.com/posts/mLvxxoNjDqDHBAo6K/claude-s-new-constitution
Biology-based brain model matches animals in learning, enables new discovery https://news.mit.edu/2026/biology-based-brain-model-matches-animal-learning-enables-new-discovery-0122
Relational Transformer: Toward Zero-Shot Foundation Models for Relational Data https://arxiv.org/abs/2510.06377
Composing Weight and Data Sparsity in MoE https://www.perceptron.inc/blog/composing-weight-and-data-sparsity-in-moe
AI’s inability to continually learn remains one of the biggest problems standing in the way of truly general purpose models. Might it soon be solved? https://www.transformernews.ai/p/teaching-ai-to-continual-learning
LLMs interpret plots well, until expectations interfere https://posit.co/blog/llm-plot-interpretation/
The UK government is backing AI that can run its own lab experiments https://www.technologyreview.com/2026/01/20/1131462/the-uk-government-is-backing-ai-scientists-that-can-run-their-own-experiments/ [no paywall: https://archive.is/wwRDn]
Designing AI-resistant technical evaluations https://www.anthropic.com/engineering/AI-resistant-technical-evaluations
Clarifying limitations of time horizon https://metr.org/notes/2026-01-22-time-horizon-limitations/
Every Benchmark is Broken https://www.lesswrong.com/posts/HzjssjeQqhf3kRw9r/every-benchmark-is-broken
Kristalina Georgieva,head of the IMF at Davos: ‘We expect over the next years, in advanced economies, 60% of jobs to be affected by AI, either enhanced or eliminated or transformed. 40% globally. This is like a tsunami hitting the labour market.’ https://youtu.be/F_bgrL-kVtE?si=XUs7Z8rwuYCWbbhu&t=204
Intelligence and memorization
This should be obvious. But if you need overwhelming evidence, check this: https://youtu.be/nJPERZDfyWc
Human creativity is based on thousands of years of cultural evolution, many years of upbringing, and hundreds of hours of search and trial and error. By the time a human reaches 18 years of age, they have been “trained” on approximately 20,000 to 70,000 Terabytes (20-70 Petabytes) of raw multimodal data. All this happened while they were grounded in physical reality and received direct feedback from their actions. And then there is the evolutionary prior, high-quality genetic data that has been fine-tuned over hundreds of millions of years.
So no, humans don’t just magically pull out-of-distribution data from the platonic realm.
Compression as intelligence
Consider this infinite sequence: ABABABABABABAB…
What comes next? Easy: A. You’ve spotted the rule: it alternates.
That’s compression. Instead of listing every letter, you replace a long string with a short description: “repeat AB”. The better your description predicts the data, the fewer bits you need to store it. So good compression and good prediction are two sides of the same coin.
The best compression looks like “I understand what’s going on.” You can’t compress well unless you’ve captured the rule that generated the data.
This is why compression is a big slice of intelligence. A machine that can compress the complexities of the world into a tiny file must carry a rich internal model. The machine essentially has to be a world simulator.
Deep learning is powerful largely because it learns such models. Add a “competence loop” on top (logical tools, search, self-checking, and goal-directed exploration) and you get intelligent systems that don’t just predict, but also solve and discover.
P.S. This isn’t just a metaphor but a mathematical theory: better compression -> better prediction -> better world-model -> better decisions. AI pioneer Marcus Hutter formalized this with his model of “Universal Artificial Intelligence” (AIXI) and backed it up with the Hutter Prize, which awards cash to anyone who can compress a snapshot of Wikipedia better than the current record.
Synthetic data

Just one note about synthetic data. It is completely a real thing that works.
The basic principle is that you turn compute into data by searching a space, and you turn that data into intelligence by compressing the winning structure into a policy/model.
What’s important here is that the generated data needs to be under strong ground-truth pressure. Just recycling leads to collapse/degradation. But if you use strong filters like formal proofs, tests, execution, adversarial games, tool feedback, you get high-quality training data that can be fed back into the model. In other words, “synthetic” is not the problem, but unfiltered synthetic data without a strong verifier/ground truth is.
This works best for math and programming. It is entirely possible to bootstrap high-quality data for both. And since everything else is downstream of math and programming, this is a big deal.
Lots of people are reasonably convinced that Anthropic already trains on agent traces (Claude Code trajectories). Since you can verify if code works, these reason-act-observe trajectories can be filtered.
This isn’t magic. Selection pressure creates information. Search (lookahead, exploration, variation) can discover actions outside the current distribution. In systems like AlphaEvolve, candidate code changes are evaluated by tests/benchmarks/performance signals. Only improvements survive.
In short:
Step 1: Improve with compute (search / exploration / evolution / self-play / proposer-solver-verifier loops).
Step 2: Compress into weights (training / distillation).
Step 3: Go to step 1.
Miscellaneous
Evolution of cortical neurons supporting human cognition: “a shift in complex computation from networks to single neurons and even to dendrites might be a defining feature of human cortical evolution.” https://www.cell.com/trends/cognitive-sciences/fulltext/S1364-6613(22)00208-X
Bizarre 400-million-year-old fossil was an unknown life form https://www.science.org/content/article/bizarre-400-million-year-old-fossil-was-unknown-life-form
Room-Temperature Superconductivity at 298 K in Ternary La-Sc-H System at High-pressure Conditions https://arxiv.org/abs/2510.01273
“I Probably Shouldn’t Have Touched Consciousness” | Roger Penrose https://www.youtube.com/watch?v=92-02TOjntI
Another Jeff Bezos company has announced plans to develop a megaconstellation https://arstechnica.com/space/2026/01/blue-origin-we-want-to-have-a-megaconstellation-too/
A quick, elegant derivation of Bayes’ Theorem https://www.lesswrong.com/posts/GjkqijXHakMyDxF9e/a-quick-elegant-derivation-of-bayes-theorem
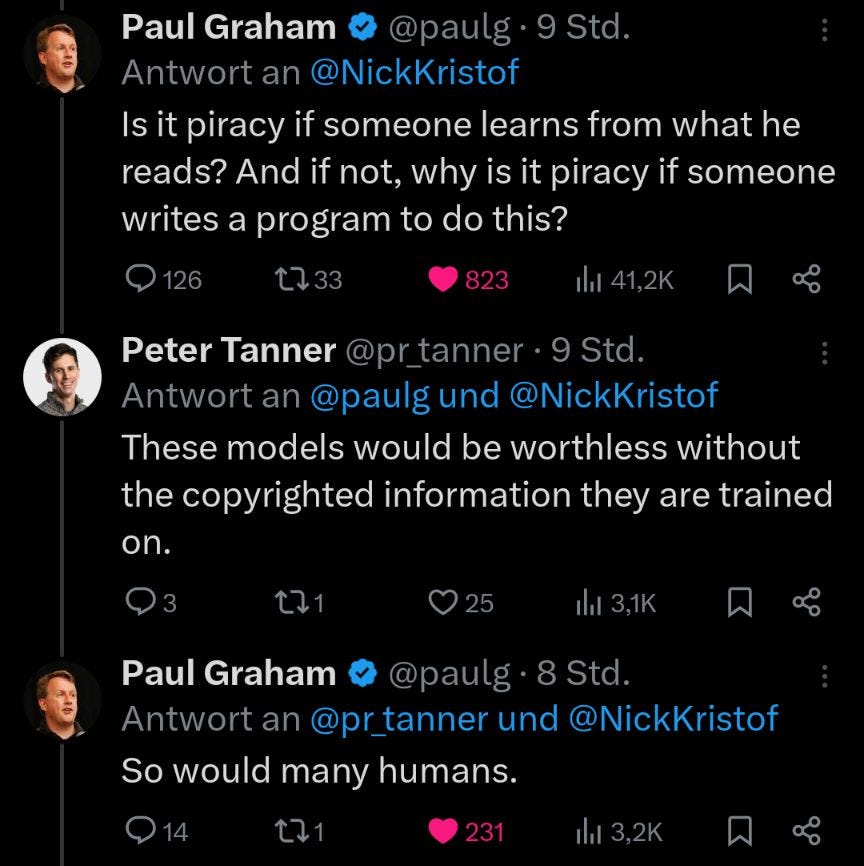
my recent compression https://whyweshould.substack.com/p/copyright