Links for 2026-01-09

Full AI solution to an Erdős problem
Terence Tao has a page that “collects the various ways in which AI tools have contributed to the understanding of Erdős problems.”
Today, the first autonomously AI generated / formalized Erdos problem was added. A combination of Aristotle and GPT 5.2 Pro was used to achieve this.
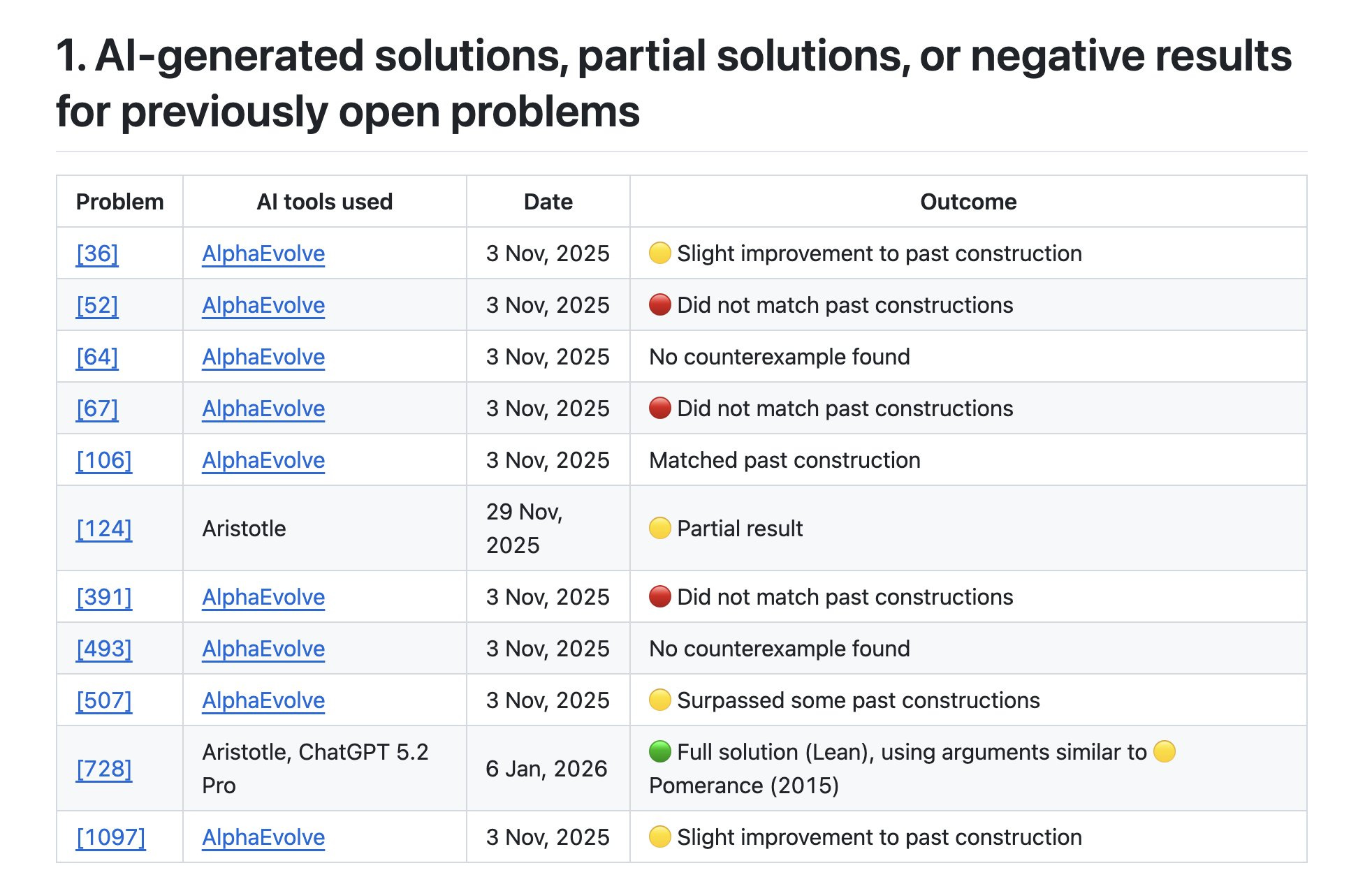
AI contributions to Erdős problems: https://github.com/teorth/erdosproblems/wiki/AI-contributions-to-Erd%C5%91s-problems
Read more: https://mathstodon.xyz/@tao/115855840223258103
P.S. Remember that math is amenable to self-generated (“synthetic”) training data because you can build very strong verifiers that can mechanically check whether a purported proof is valid.
For one of many data points, see age 14 of Google’s AlphaGeometry2 paper:
Our geometry experts and IMO medalists consider many AlphaGeometry solutions to exhibit superhuman creativity.
So an AI can generate its own training signal by trying proofs, checking them, and reinforcing what works (analogous to self-play in chess/Go, where AI is strongly superhuman now). This makes AI that is “superhuman at math” a plausible goal.
Propose, Solve, Verify
Propose, Solve, Verify (PSV): Self-play for code with proofs, not tests
Most AI coding systems learn from unit tests: they write code, run it on a few examples, and get rewarded if it passes. But tests are incomplete. Code can pass all tests and still be wrong on rare inputs. So the AI can learn “cheap tricks,” and those errors can spread during training.
PSV replaces this with a much stricter judge: formal verification. Instead of checking a handful of examples, a verifier tries to prove mathematically that the program meets the specification for all possible inputs.
The PSV loop
1. Propose: write the “what”
The Proposer invents a new task by writing a specification (a precise description of what the program must do).
Here is the crucial idea: the proposer does not need to be a genius that can foresee what will stump a superhuman solver (like designing a benchmark for Terence Tao). PSV relies on a simpler asymmetry:
It’s often easy to state constraints.
It’s often harder to satisfy them (and prove you did).
A proposer can cheaply say: “Sort this list,” or “Sort it and keep it stable,” or “Sort it, return an index mapping, and prove nothing was lost or duplicated.” Stacking constraints is much easier to describe than to implement and prove them correct.
2. Solve: do the “how”
The Solver tries to write the program (and the proof-style annotations the verifier needs). It samples many attempts (like trying many “mutations”).
3. Verify: harsh selection
A formal verifier checks each attempt. Only solutions that are provably correct count as wins. This is the key difference from unit tests: passing isn’t “it worked on a few examples,” it’s “it’s correct for everything.”
4. Learn: keep the survivors
The solver then trains on those verified wins, becoming more likely to produce correct solutions next time.
How problems get harder without a smarter proposer: PSV makes “hard” relative, not absolute. Instead of the proposer guessing difficulty in advance, the system measures it empirically:
If the solver verifies solutions for a spec 90% of the time, it’s easy.
If it verifies only 10% of the time, it’s hard.
If it never verifies, it’s too hard (for now).
The proposer is shown examples labeled EASY / MEDIUM / HARD and asked to generate new specs at a target difficulty. If the solver starts succeeding too often, the system nudges the proposer toward harder specs (more conditions, tighter guarantees). If nothing succeeds, it nudges back.
So the proposer doesn’t need to “outthink” the solver. It just needs to generate many candidate specs, while the system uses feedback (pass rates) to keep the difficulty near the frontier (like a teacher who adjusts homework based on how the student actually performs).
Where the intelligence increase comes from.
PSV is basically evolution with a very strict referee:
Variation: many proposed problems, many attempted solutions.
Selection: only solutions that pass the verifier survive
Inheritance: the solver trains on the survivors.
Moving frontier: as the solver improves, yesterday’s “hard” becomes today’s “medium,” so the system keeps pushing forward.
That’s why self-play works here: the verifier prevents the loop from “learning lies,” and the proposer and feedback mechanism keep generating fresh challenges just beyond the current capability.
A sign it scales: In the paper, generating more proposed tasks per round helped. Increasing from 1,000 to 32,000 proposed questions raised MBPP pass@1 from 22.3% to 44.3%. This is consistent with the idea that more self-generated practice plus strict verification produces real capability gains.
Paper: https://arxiv.org/abs/2512.18160
Epiplexity
How can next-token prediction on human text lead to superhuman skills? How can synthetic data sometimes beat “real” data? And how did AlphaZero learn so much from nothing but the rules of chess? Classic information theory seems to say this shouldn’t happen. Yet it clearly does.
The problem is that traditional information theory assumes an observer with unlimited computing power. An unbounded observer can crack any code and reverse any function instantly. To them, a cryptographically encrypted message is “simple” because they can easily find the seed that generated it, distinguishing it easily from pure random noise. If you ignore time, ciphertext isn’t “random”, it’s the output of a short recipe plus a key. But if you can’t afford the computation, it behaves like noise.
But AI systems don’t have infinite compute. They’re bounded. And once time and compute matter, a new distinction appears:
Time-Bounded Entropy (Randomness): Data that is computationally hard to predict. This includes true noise, but also things like encryption keys or complex hashes that look random to a neural network.
Epiplexity (Structure): Patterns, abstractions, and rules that a model can actually learn and use to compress the data within a reasonable time.
They formalize it roughly like this:
Find the smallest model that can predict the data within a time limit.
The size of that model is epiplexity. Whatever remains unpredictable is time-bounded entropy.
This solves the paradox. Random noise has high entropy but low epiplexity because no amount of computing power helps you find a pattern, so the model learns nothing. Meanwhile, a strategy game or a textbook has high epiplexity. It forces the model to build complex internal circuits (shortcuts and concepts) to predict the data efficiently.
A neat example from the paper: training a model to predict chess moves is standard. But training it to predict the game in reverse (inferring moves from the final board) is computationally harder. This difficulty forces the model to learn deeper representations of the board state (higher epiplexity), which actually improves its performance on new, unseen chess puzzles. The computation "created" information by converting the implicit consequences of the rules into explicit, usable structures (epiplexity) that the model can now use to play well.
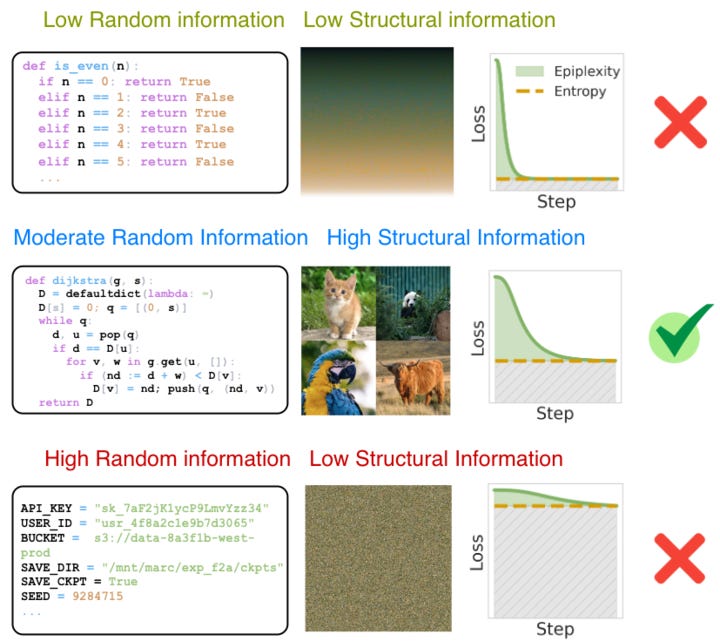
In summary: The value of data isn’t just about how unpredictable it is. It’s about how much reusable structure it induces in a learner that has real-world limits.
Epiplexity is the amount of structure a model is worth learning because it reduces prediction error enough to justify the added complexity under a time limit.
Read the paper: https://arxiv.org/abs/2601.03220
Spatiotemporal abstractions
Imagine trying to teach a robot to navigate a complex maze.
Traditional training uses trial and error. The robot tries random movements and gets a reward if it succeeds. The problem is that the AI model controlling the robot isn’t deciding on meaningful steps like “walk to the door.” Instead, it chooses tiny motor commands, similar to individual muscle twitches.
If the robot has to guess the correct sequence of millions of muscle twitches to solve a maze by random chance, it will fail every time. It flails around, never reaches the goal, and learns nothing.
To solve this, Google researchers first taught the robot simply by having it watch experts. The robot learned to predict the expert’s next split-second movement.
Surprisingly, the researchers found that while the robot was learning these tiny movements, it was secretly building a map of the bigger picture. To predict the next twitch accurately, the robot internally needed to know “I am currently walking toward the red door.”
The lead researcher explains this difference using coffee. Making a cup of coffee involves tiny, split-second hand movements. But it also involves massive, long-term goals (like driving to the store to buy beans). Traditional robots get stuck optimizing the hand movements. This new approach allows them to “plan the trip.”
The researchers created a way to tap into these hidden internal plans. Instead of letting the AI decide every single muscle movement 100 times a second, they built a “steering wheel” that forces the AI to pick one of those high-level intentions (like “go to the red door”) and stick with it for a while.
This works for the same reason humans don’t plan their day by focusing on individual footsteps. Instead of searching through trillions of twitch combinations, the AI only has to choose between a few high-level plans. Because each choice lasts longer and does something useful, the robot stops flailing and actually reaches the goal, allowing it to finally learn from its success.
The researchers believe this architecture mimics human biology. The main AI model acts like the Cortex (constantly predicting what happens next based on what it sees), while the new “steering wheel” mechanism acts like the Basal Ganglia (nudging the cortex toward rewarding goals and habits).
In summary: Think of the “steering wheel” as a filter. Without it, the robot considers every possible muscle twitch at every millisecond (a search space so vast it is effectively infinite). By locking in a high-level intention, the steering wheel prunes the search space. It forces the robot to ignore the billions of random twitch combinations that don’t help reach the current sub-goal, making low-level actions goal-directed rather than random.
Paper: https://arxiv.org/abs/2512.20605
Talk: https://www.youtube.com/watch?v=cx_MIhvAOYM
Digital Red Queen: Adversarial Program Evolution in Core War with LLMs
What happens when you let an LLM write tiny computer programs that compete for control of a virtual computer’s memory?
Setup:
The environment: A chaotic “toy computer” where programs live inside shared memory. Because the program’s instructions are stored in the same place as its working data, programs can overwrite (sometimes even copy) themselves, and they can try to corrupt their opponents.
The Algorithm: A self-play algorithm inspired by the Red Queen hypothesis in evolutionary biology, which suggests organisms must constantly adapt just to maintain their relative fitness against evolving competitors.
The Process: Instead of training against a static objective, the algorithm evolves a lineage of warriors. In each round, an LLM generates a new warrior specifically designed to defeat all previous versions in the lineage.
Outcome: As the evolutionary arms race progresses, the warriors become increasingly robust and general-purpose, capable of defeating human-designed strategies they were never explicitly trained against.
Read the paper: https://sakana.ai/drq/
AI
A comprehensive thesis on an imminent explosion of the robotics industry. In other words, robotics is going to start working much, much faster than people expect. The cost of robots is predicted to crash, eventually costing closer to an iPhone than a car, due to lower material requirements and “robots making robots”. The primary economic outcome will be massive deflation as the cost of labor drops to near zero. https://finaloffshoring.com/
ChatGPT for Healthcare: “Over the past two years, we’ve partnered with a global network of more than 260 licensed physicians across 60 countries of practice to evaluate model performance using real clinical scenarios. To date, this group has reviewed more than 600,000 model outputs spanning 30 areas of focus. Their continuous feedback has directly informed model training, safety mitigations, and product iteration. ChatGPT for Healthcare went through multiple rounds of physician-led red teaming to tune model behavior, trustworthy information retrieval, and other evaluations.” https://openai.com/index/openai-for-healthcare/
AI now predicts 130 diseases from 1 night of sleep https://www.nature.com/articles/s41591-025-04133-4
Scaling Open-Ended Reasoning To Predict the Future https://openforecaster.github.io/
Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space https://arxiv.org/abs/2512.24617
LLMs Reproduce Human Purchase Intent via Semantic Similarity Elicitation of Likert Ratings https://arxiv.org/abs/2510.08338v3
Why LLMs Aren’t Scientists Yet. https://www.lesswrong.com/posts/y7TpjDtKFcJSGzunm/why-llms-aren-t-scientists-yet
Anthropic’s new update makes coding agents self-healing https://venturebeat.com/orchestration/claude-code-2-1-0-arrives-with-smoother-workflows-and-smarter-agents
Claude Code and What Comes Next https://www.oneusefulthing.org/p/claude-code-and-what-comes-next
An AI revolution in drugmaking is under way https://www.economist.com/science-and-technology/2026/01/05/an-ai-revolution-in-drugmaking-is-under-way [no paywall: https://archive.is/Si71E]
JPMorgan is cutting all ties with proxy advisory firms and replacing them with AI to help cast shareholder votes https://www.wsj.com/finance/banking/jpmorgan-cuts-all-ties-with-proxy-advisers-in-industry-first-78c43d5f [no paywall: https://archive.is/Ttc8z]
How Judges Are Using AI to Help Decide Your Legal Dispute https://www.wsj.com/tech/ai/how-ai-could-help-decide-your-next-legal-dispute-9cb12517 [no paywall: https://archive.is/nmelA]
Stack Overflow’s forum is dead thanks to AI, but the company’s still kicking... thanks to AI https://sherwood.news/tech/stack-overflow-forum-dead-thanks-ai-but-companys-still-kicking-ai/
First theoretical physics paper to credit an AI assistant https://arxiv.org/abs/2601.02484
Real poetry by AI https://gwern.net/fiction/lab-animals
Neuro(tech)
These Hearing Aids Will Tune in to Your Brain https://spectrum.ieee.org/hearing-aids-biosignals
If an event is more likely to occur at a certain point in time, the brain tracks the time until it occurs more precisely https://www.mpg.de/25980090/brain-estimates-probabilities-of-events
A brain-inspired approach to scientific computing https://newsreleases.sandia.gov/nature-inspired-computers-are-shockingly-good-at-math/
The End of Privacy: Tracking Technology is Everywhere Now https://www.youtube.com/watch?v=UYWjgceclS4
Miscellaneous
Explaining Cloud-9: A Celestial Object Like No Other https://www.centauri-dreams.org/2026/01/07/explaining-cloud-9-a-celestial-object-like-no-other/
A tiny number of hyper-prolific individuals are responsible for a massive percentage of public complaints, effectively "monopolizing" government resources and taxpayer money. https://marginalrevolution.com/marginalrevolution/2026/01/the-tyranny-of-the-complainers.html
In “Being Nicer than Clippy,” Joe Carlsmith argues that our approach to AI alignment should be guided by “niceness” (a specific human virtue of respecting the preferences and boundaries of others) rather than just a competitive “battle of the utility functions.” https://joecarlsmith.com/2024/01/16/being-nicer-than-clippy
Gamified War in Ukraine: Points, Drones, and the New Moral Economy of Killing https://warontherocks.com/2026/01/gamified-war-in-ukraine-points-drones-and-the-new-moral-economy-of-killing/
So what is Chat GPT's Erdős number?