Links for 2026-01-03

Principal engineer at Google lauds Claude
AI
ByteDance: Scaling vision-language-action (VLA) models to high-DoF dexterous hands has long been a “holy grail” challenge due to the high-dimensional action space and data scarcity. As a wrap up of the year 2025, we are releasing GR-Dexter, a holistic hardware-model-data framework for generalist manipulation on a bimanual dexterous-hand robot. https://byte-dexter.github.io/gr-dexter
ByteDance: A next-generation folding model that scales up model capacity through width scaling and large-scale data distillation. https://seedfold.github.io/
ByteDance plans to spend $14 billion on NVIDIA H200’s next year to keep up with demand. Reuters is also reporting this morning that Jensen has approached TSMC to ramp up production, as Chinese companies have placed orders for more than 2 million H200’s in 2026. https://www.reuters.com/world/china/nvidia-sounds-out-tsmc-new-h200-chip-order-china-demand-jumps-sources-say-2025-12-31/ [no paywall: https://archive.is/y1PVl]
In a new paper, China’s DeepSeek makes a rare kind of improvement: a low-level architectural tweak. It effectively allows the model to learn its own wiring diagram. It lets the model learn how strongly different layers and parallel streams should mix information, unlocking better reasoning capabilities with negligible added computational cost. It builds on ByteDance’s Hyper-Connections, but adds constraints that keep training stable even at large scale, with only modest overhead. If the results hold up, this creates a powerful new lever for AI progress. https://arxiv.org/abs/2512.24880
Deep Delta Learning (DDL), introduced by researchers from Princeton and UCLA, is a novel neural network architecture that generalizes the standard residual connection using geometric linear algebra. [PDF] https://yifanzhang-pro.github.io/deep-delta-learning/Deep_Delta_Learning.pdf
The Missing Layer of AGI: From Pattern Alchemy to Coordination Physics https://arxiv.org/abs/2512.05765
Humans learn to generalize without losing the ability to memorize later. Transformers, by contrast, do not show the same benefit: when training shifts toward memorization, earlier generalization does not reliably carry over. https://www.nature.com/articles/s41562-025-02359-3
Innovation is a phase transition triggered by constraint failure, where “flaws” become the catalyst for a system to expand its intelligence and degrees of freedom. https://x.com/ProfBuehlerMIT/status/2006687082769424595
A Network of Biologically Inspired Rectified Spectral Units (ReSUs) Learns Hierarchical Features Without Error Backpropagation https://arxiv.org/abs/2512.23146
Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space https://arxiv.org/abs/2512.24617
Recursive Language Models: the paradigm of 2026 https://www.primeintellect.ai/blog/rlm
DiffThinker: Towards Generative Multimodal Reasoning with Diffusion Models https://arxiv.org/abs/2512.24165
The latest models can do “3 logical steps” (3-hop composition of factual queries) entirely within their latent space. For example, Gemini 3 Pro can answer 46% of 2-hop queries and 18% of 3-hop queries. For comparison, GPT-4 gets under 10% of 2-hop queries right. This suggests that “latent” intelligence is scaling alongside overall model capability. With filler tokens (extra “thinking space”), Gemini 3 Pro rises to 60%/34%. Performance is near chance on 4-hop for all models tested. https://www.lesswrong.com/posts/aYtrLhoZtCKZnfBvA/recent-llms-can-do-2-hop-and-3-hop-latent-no-cot-reasoning
Alethfeld: Rigorous Proofs via Adversarial AI Agents https://tjoresearchnotes.wordpress.com/2026/01/02/the-adversarial-prover-a-skeptics-approach-to-llm-assisted-mathematics/
Next Big Paradigm in AI: Titans, Atlas and Nested Learning - Ali Behrouz, Deepmind https://www.youtube.com/watch?v=3WqZIja7kdA
The “Compute Theory of Everything” in AI: scaling hardware and training runs keeps producing qualitative capability jumps, echoing older arguments from Moravec and Sutton’s “Bitter Lesson.” https://samuelalbanie.substack.com/p/reflections-on-2025
Taiwan war timelines might be shorter than AI timelines https://www.lesswrong.com/posts/ozKqPoA3qhmrhZJ7t/taiwan-war-timelines-might-be-shorter-than-ai-timelines
Japan to Quadruple Spending Support for Chips, AI in Budget https://www.bloomberg.com/news/articles/2025-12-26/japan-to-quadruple-spending-support-for-chips-ai-in-budget [no paywall: https://archive.is/hVfQ2]

A roundup of some AI predictions for 2026
Varun Mohan, Ronak Malde (Google DeepMind), and Sholto Douglas (Scaling RL Anthropic): There is probably going to be huge progress on continual learning.
Hieu Pham (OpenAI): 2026 will witness a millenium problem being solved majorly by AI.
Brett Adcock (Figure): Humanoid robots will perform unsupervised, multi-day tasks in homes they’ve never seen before - driven entirely by neural networks. These tasks will span long time horizons, going straight from pixels to torques.
Logan Kilpatrick (Google AI): 2026 is going to be a huge year for embodied AI / or put differently, we are going to see a lot more robots in the real world soon.
David A. Dalrymple (Programme Director at the UK’s Advanced Research + Invention Agency): By about December 2026, AI will likely be able to do most of the work of improving AI algorithms itself. The time it takes for capabilities to double could drop to around 70–80 days.
Stephen McAleer (AI researcher at Anthropic): We will have automated AI research very soon and it’s important that alignment can keep up during the intelligence explosion.
Jack Clark (Anthropic): By summer of 2026 it will be as though the digital world is going through some kind of fast evolution, with some parts of it emitting a huge amount of heat and light and moving with counter-intuitive speed relative to everything else.
See also: 2025 in AI predictions https://www.lesswrong.com/posts/69qnNx8S7wkSKXJFY/2025-in-ai-predictions
Miscellaneous
A significant step toward scalable atomically precise manufacturing: Inverted-Mode Scanning Tunneling https://arxiv.org/abs/2512.24431
Doomslayer: 1,084 Reasons the World Isn’t Falling Apart https://humanprogress.org/doomslayer-1084-reasons-the-world-isnt-falling-apart/
“Winning”
A brilliant scientist was walking down the street, lost in thought about his breakthrough cancer therapy. Suddenly, he was shot in the head from behind. The robber, a low-IQ drug addict, wanted the scientist’s wallet.
Who “won”? In one narrow sense, the robber got what he wanted. But if “winning” means an outcome you’d actually choose from the inside, almost no one would trade places with him.
Now imagine a giant asteroid hits Earth tomorrow and wipes out humanity. Only cockroaches survive. Did the cockroaches win? They persisted. But at the end of the day, they’re still just cockroaches.
We talk this way all the time: “He fought bravely, but in the end, the cancer won.” But “winning” is a value word. It only makes sense relative to a perspective. When we say “cancer won,” we’re imagining a perspective that doesn’t exist. And when we say an evil person “won” because he survived or got what he wanted, we’re quietly switching to a perspective most of us refuse to inhabit.
Life isn’t a football game. Survival and resource capture don’t automatically equal triumph. Sometimes the best lose, and sometimes what survives isn’t worth being. “Real winning” isn’t a property of outcomes; it’s a relationship between an outcome and a set of values.
Three-Hour Special Military Operation

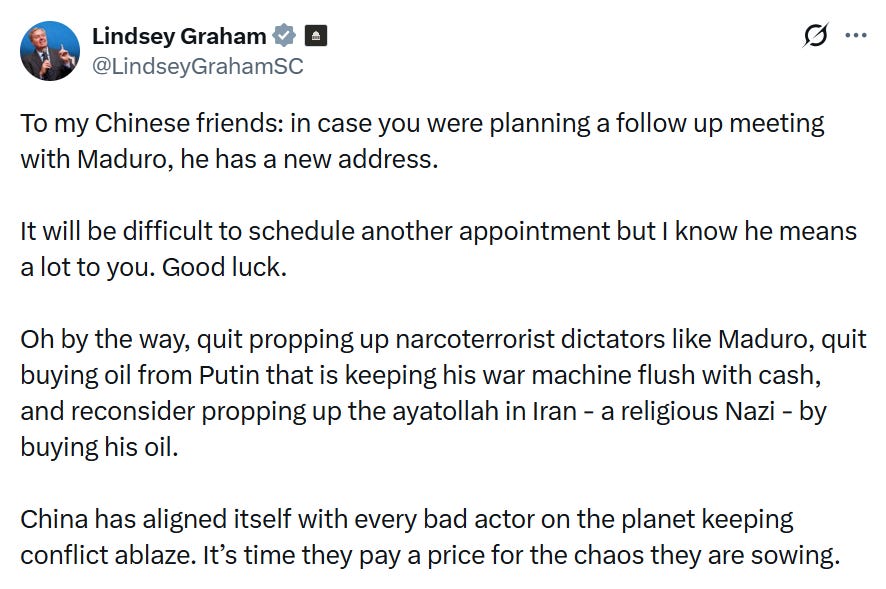
‘We are going to run the country’: Trump says U.S. will govern Venezuela until there’s a ‘proper transition’ https://www.nbcnews.com/politics/white-house/trump-venezuela-nicolas-maduro-strikes-run-country-transition-military-rcna252044
Trump was such a sooky-eyed kitten when the drone supposedly was sent towards one of Putins many palaces... but stealing some one from his bed is just fine.... history has become one damn narcissist after another